
This used to appear on ontheroad.nicksellen.co.uk which was all about a bike tour I made around the UK in 2011/2012.
Managing clouds
09 October 2011I just got back from a visit to London – the purpose of the trip was to carry on with a project I had started earlier in the year before I left on my trip. I had made most of it but it was not sufficiently ready to put into production without a little bit of a nudge from me.
This is going to be a reasonably technical post explaining how the system works.
The old way
The original way to provision services for clients was all command line based. In the early days of the platform this meant running sun/gnu/etc commands directly (e.g. zonecfg -z somezone create, or zfs create rpool/zones/somezone). These got abstracted over time to a set of bash scripts to perform “logical” operations (e.g.”provision a new client zone”) which would do all the underlying work required. When I started this project the number of those bash scripts had massively increased and the whole mechanism was bursting at the seams really. Over 50 scripts in a flat namespace is too many (especiallywithnamesthatarequitehardtoparse).
If a bash script goes wrong during execution it’s difficult to know how far it had got through – recovering from the issue would usually involve reading the script and going through step by step either undoing what it had done or finishing it off manually. It would be possible to write them so they can handle these scenarios – it’s not really the job of a totally stateless script (i.e. no db), and bash is the wrong language for this level of complexity (bash arrays are ugh).
The new way
The solution needed to be implemented fairly quickly yet flexibly – this means not writing everything from the ground up (as somewhere like Facebook would have the resources to do) but using other modules of software where possible.
It should have a central repository of information to replace spreadsheets and make accounting and auditing easier. It should have a limited and well documented set of logical commands that are the same to use regardless of the underlying implementation. It should handle unexpected scenarios and errors gracefully in a way they can be recovered from. As a bonus it should only require modification of some ACL modification to allow clients to use it.
MCollective and remote execution
A core task is how to securely yet flexibly run commands from a control node on any number of remote nodes (storage servers, VM hosts, etc).
A previous system I created used SSH from the control node to execute commands on remote nodes, Solaris RBAC limited the commands that could be run. However it wasn’t good enough for this system – SSH loops to query multiple nodes don’t scale well, security is hard to ensure (lots of SSH keys to manage), no obvious way for a node to initiate communication back to the control node, and RBAC isn’t enough (I need to limit how commands are run not just which ones).
Enter mcollective.
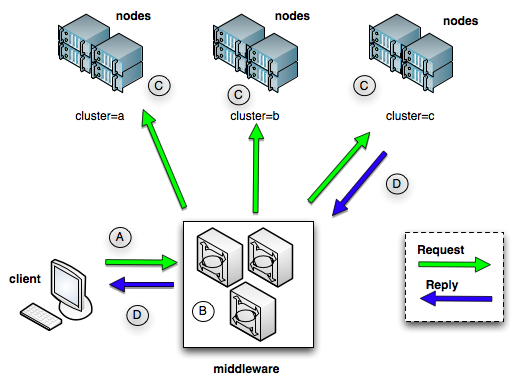
basic mcollective diagram
It allows query of any number of nodes simultaneously, access is easy (one middleware address and port), security is improved (mostly because you can only run the commands that have been implemented with specific validated inputs and outputs), and you get mechanisms for discovery (auto-finding new nodes), and registration (keeping a central database of assets/resources) for free. Also it’s free, open source, and ruby based meaning I can easily view/modify the inner workings if required.
Abstractions and APIs
The old way had no separation of logical operations from the implementation of them. The new way has multiple layers of separation and defined APIs between them (sorry for the crummy formatting below).
[person] <-REST API-> [central node] <-command API-> [external command] <-mcollective API-> [command execution]
This makes it possible to replace any of the component parts (within [square brackets]) without changing any of the other parts.
UI
Originally I was just going to create a REST API – it would be up to somebody else to work out the best way to interact with it. I hate HTML and CSS, actually I hate all web development that involves the server sending full HTML (perhaps even any HTML) on each page load. I want the browser to own control of the interface to ensure it can be responsive and to do this it must have client side code to fetch data not HTML.
For these reasons I’ve been curious about trying out the various client-side heavy javascript frameworks that have emerged recently as it is exactly fits the model I want. The two that most stood out to me were sproutcore and backbone.js. I had previously made a proof of concept app with sproutcore and found it very powerful (the bindings, datastore, and calculated properties are great) but cumbersome (quite a lot of new words/concepts, lots of KBs to download, hard to reuse my existing HTML/CSS knowledge).
With backbone however I managed to create an entire UI over a weekend and it took no more than a week to get an interface with 13 list views + 13 detail views, somewhere in the region of 80 API calls using pretty forms with client-side validation, bookmarkable and “back-button-in-your-browser”-able URLs, recent items view, and fully linked detail views (semantic web style) allowing you to easily navigate around the db entities.

screenshot of the UI in action
Anyway…
I could go on but the view over Loch Lomand is looking simply beautiful in the sun ! :)
